
OpenAI представила нову версію генератора зображень DALL-E 3 – він краще розуміє людей











Компанія OpenAI презентувала Dall-E 3, останню версію свого інструменту перетворення тексту на зображення, який використовує надзвичайно популярний чат-бот із штучним інтелектом ChatGPT для заповнення підказок. Про це повідомляє Reuters.
Dall-E 3 буде доступний клієнтам ChatGPT Plus та Enterprise у жовтні. Користувачі можуть ввести запит на зображення та налаштувати підказки у розмовах з ChatGPT.
«DALL-E 3 може перетворювати деталізовані запити на надзвичайно докладні та точні зображення», – йдеться у заяві компанії.
Вона з більш високою точністю дотримується «складних запитів» — наприклад, якщо користувач просить намалювати «сюжет з конкретними об'єктами та задає ставлення між ними».
OpenAI заявила, що остання версія інструменту матиме більше гарантій, таких як обмеження можливості створення контенту, що містить насильство, контент для дорослих або такий, що розпалює ненависть.
DALL-E 3 «відхилятиме» запити, в яких її просять намалювати картину в стилі художника, що нині живе (останні також можуть залишити заявку OpenAI, щоб та не використовувала їх роботи для навчання своїх майбутніх моделей). Серед інших обмежень – заборона на зображення відомих особистостей.
У гонці зі створення точних інструментів штучного інтелекту для перетворення тексту на зображення у OpenAI є кілька конкурентів, у тому числі компанії Alibaba Tongyi Wanxiang, Midjourney та Stability AI, які продовжують удосконалювати свої моделі генерації зображень.
Генерувати зображення можна буде прямо через чат-бот ChatGPT. У жовтні 2023 року модель буде доступна через API передплатникам платних тарифів ChatGPT-Plus і Enterprise. Чи з'явиться безкоштовна версія – невідомо.
Згенеровані зображення можна буде монетизувати, не отримуючи додаткового дозволу OpenAI, як і у випадку з DALL-E 2.
Розробник зазначає, що різниця як генерація особливо видно, якщо порівнювати результати, які DALL-E 2 і DALL-E 3 видають по тому самому запиту.
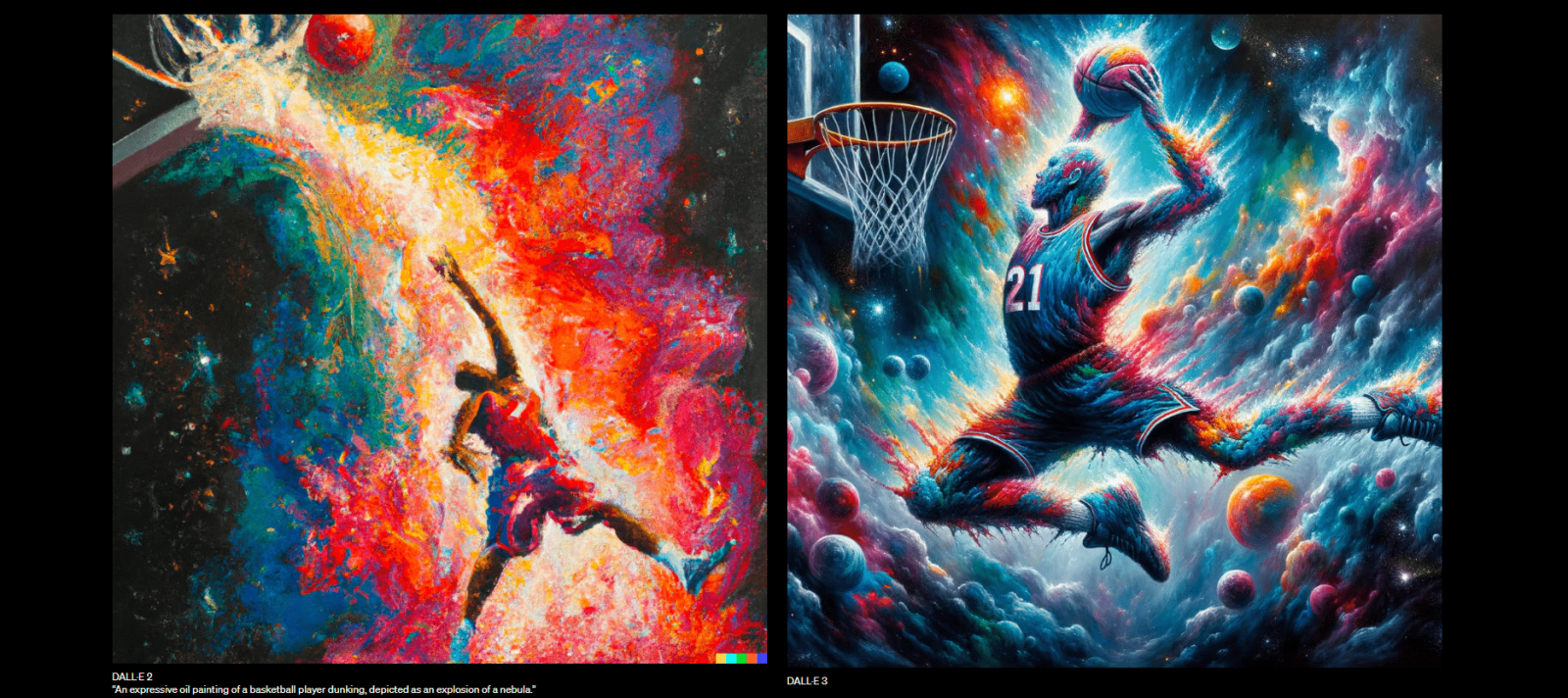
Також модель краще справляється з такими складними для штучного інтелекту дрібними деталями, як людські руки. DALL-E 3 зможе точно відобразити сцену з конкретними об'єктами і врахувати, як вони пов'язані один з одним, як показано на зображенні нижче.

OpenAI також показала інші приклади згенерованих зображень.
.jpg)
.jpg)
.jpg)
.jpg)
Підписуйтесь на наш Telegram-канал t.me/sudua та на Twitter, а також на нашу сторінку у Facebook та в Instagram, щоб бути в курсі найважливіших подій.
Читайте також











-

Благодатний вогонь прибув в Україну — першими святиню зустріли прикордонники, фото
10:54, 20 квітня 2025 -

На Полтавщині правоохоронці вилучили схрон боєприпасів в одній із лісосмуг, фото
09:24, 20 квітня 2025 -

У Києві зграю рожевих фламінго повернули на літні озерні угіддя, фото
18:43, 19 квітня 2025 -

Україна повернула з російського полону 277 захисників напередодні Великодня, фото
18:15, 19 квітня 2025 -

Побиття військового у Києві — поліція затримала ще двох підлітків, фото
14:48, 19 квітня 2025

-

У Києві покарали водія Audi, який проїхався по зустрічній смузі — відео
23:34, 21 квітня 2025 -

Володимир Зеленський привітав українців зі святом Великодня, відео
09:42, 20 квітня 2025 -

У Києві покарали водія BMW, який проїхався смугою для громадського транспорту — відео
22:00, 19 квітня 2025 -

У Єрусалимі зійшов Благодатний вогонь, відео
15:06, 19 квітня 2025


-
 суддя Шостого апеляційного адміністративного суду
суддя Шостого апеляційного адміністративного суду
